USYD - COMP 5046
Lecture 1
N-Gram LMs
The 4 ways to deal with the unseen word sequence
smoothing:

discounting:
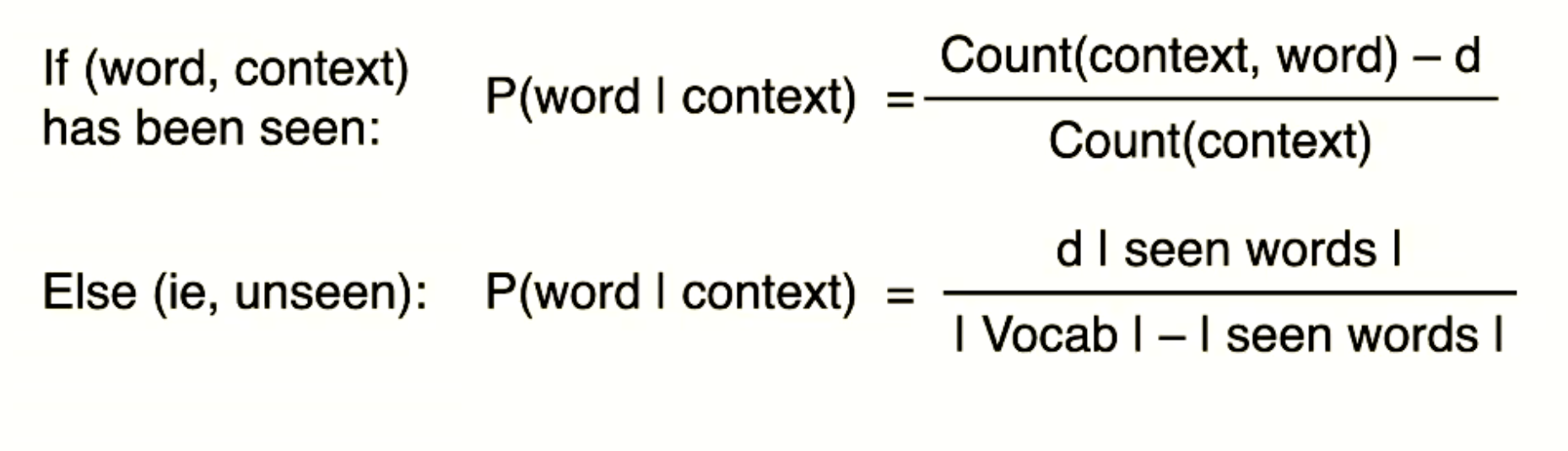
Interpolation: using the multiple N-Gram probability

Kneser-Ney smoothing:
Lecture2
Lecture3
Lecture4
Note the formula macro and micro F1 score — ass2
Not the find_best_socre initial number should be negative — ass2
directly using average will make some features vanish (+ and -), also the order is meaningless
in slide, NER page 66
labels number * length * length means:
each token in sequence is possible for start or end, that is length * length
then, each span can be predicted as each label
so, the output should be (labels * length * length)
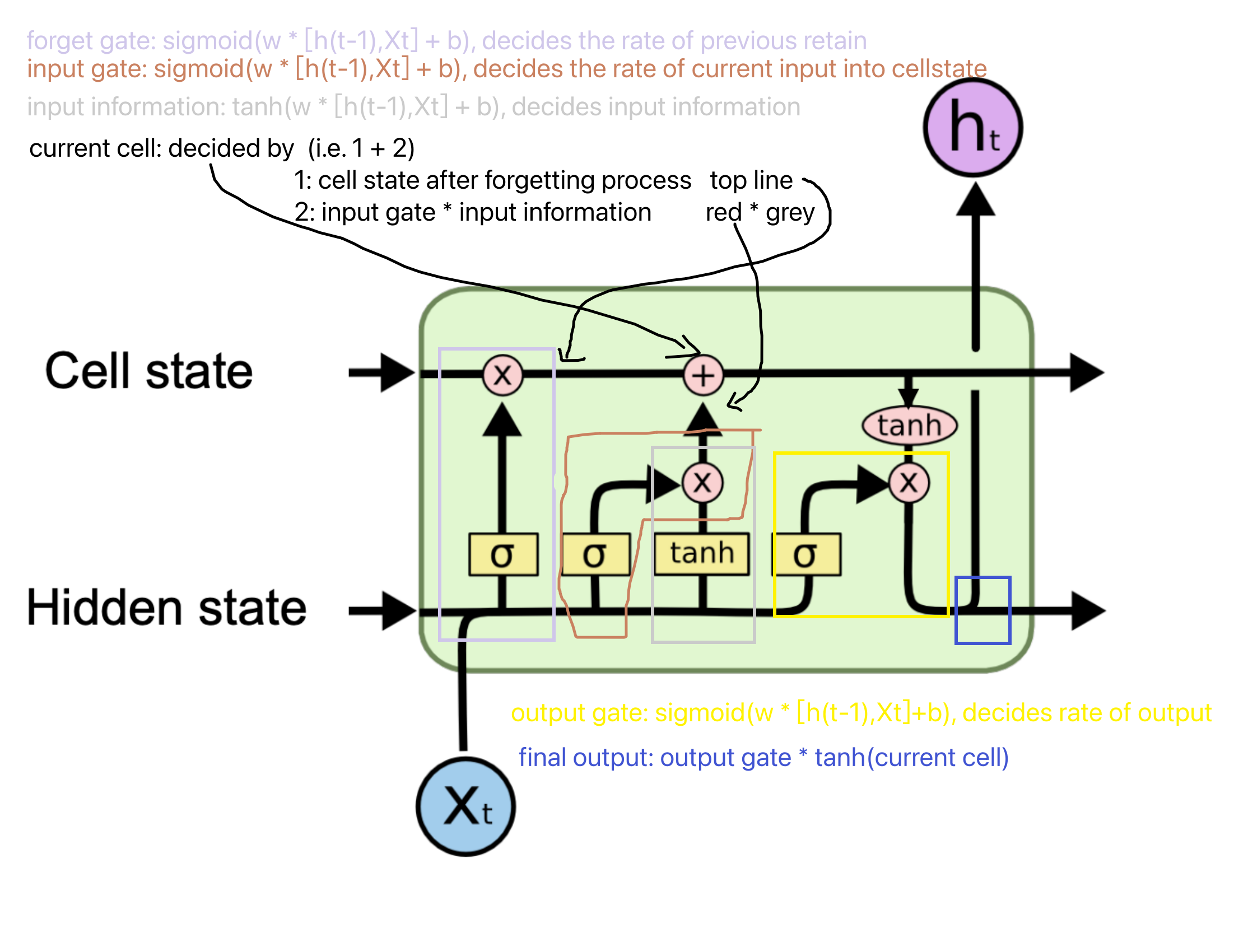
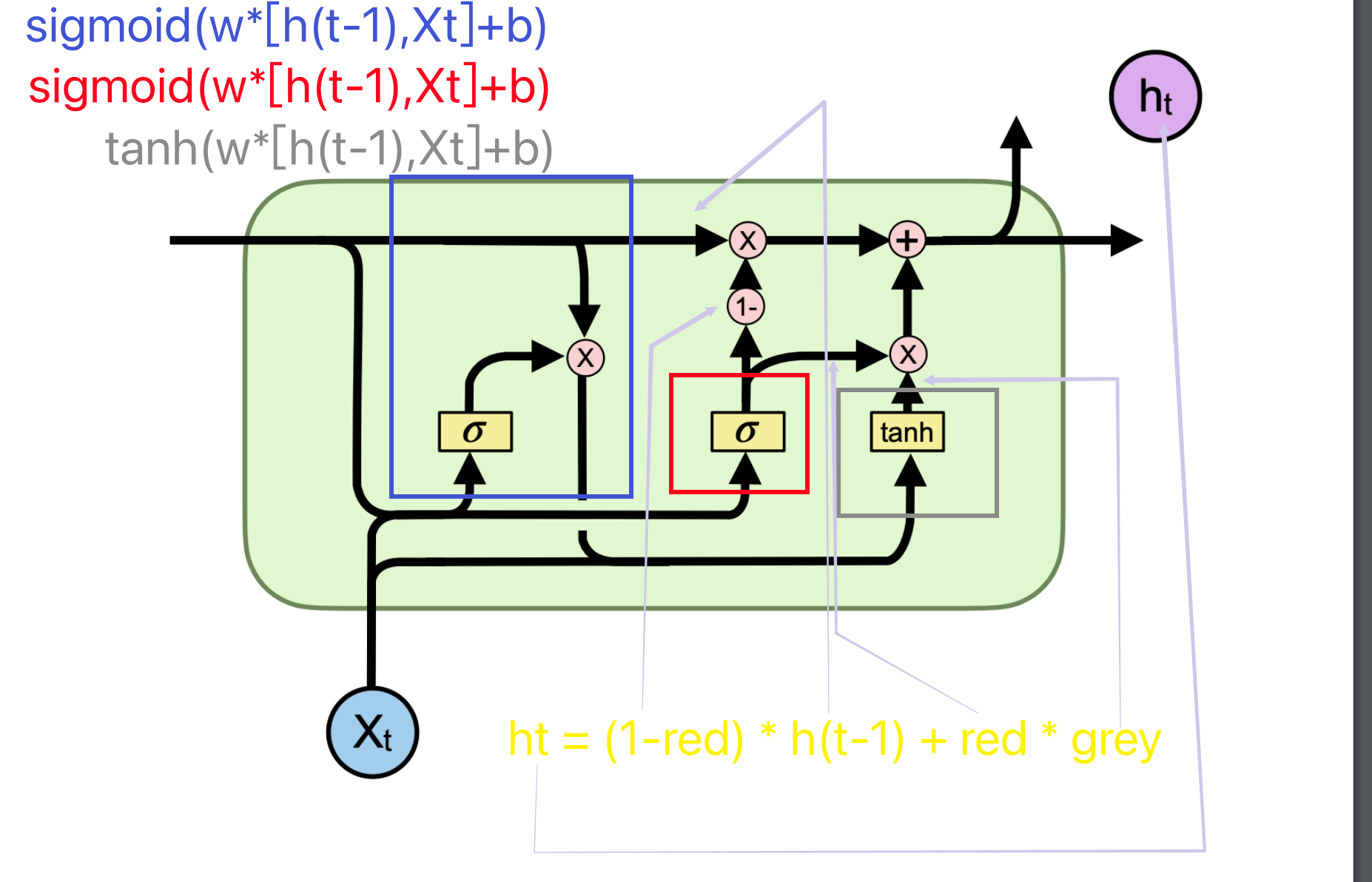
Lecture 5
beam search
in nature, greedy search is to find the local optimal solution in each step
Lecture 6
the label in current word from LSTM purely, B I O possibility(sum as 1)
score = current label p * best (previous p * transfer p)
it from
score = current label p * best (i.e. DP * transfer model)
DP refers to the optimal route in choice
transfer model refers to the Markov model
co reference
dependency parsing
Lecture 7
Lecture 8
disadvantages of self-attention
problem:
non-linear lacking
order lacking
resolve:
feedforward layer
additional position vector
issue: the length of the position vector is fixed, not flexible enough
the mask is for ignoring the future word in the training process, it lets the model know what is known in this step, and what is the prediction in this step. In math, put the infinite negative value for future words and dot the product in the current word
the multiple layers of self-attention are used to build better representation of the word
query: curve line
key: embedding word
value: passing into the weighted value
Lecture 10
data can from
fineweb
common craw
Lecture 11
Review
The content below is the missing slide week.
parsing, 句法分析, identity the grammar structure by sub-phrases
The span in the sentence called the phrase
treebanks
Method: Dependency Parsing / Grammar
compute every possible dependency to find the best score
Or, choose a way to get the best overall score
co-reference