在USYD上NLP课程的时候对于w2v一直十分的困惑,只知道其输入输出的区别以及目的,没有深究其原理以及实现方式。今天对于其中两个模块进行详细的研究,算是补齐了之前的一小块拼图。其中的两个优化方法都是对于复杂度的降低,一个是对于词表的降低,另一个是对于损失函数计算方法的降低。是通过近似和模拟的方式去考虑以实现降低的计算。写篇文章记录一下,下次忘记了有地方找(bushi (:
Word2vec
If the encoding use the one hot encoding to represent the word. The dimension will be huge, and the matrix will be sparse. Even the PCA could be applied.
Also, this way could have another limitation, that is the semantic could not be represent well. For instance, the value of COS in similar wards are 0, they show the totally different.
Thus, the word2vec come up. Its not a model, but a tool.
It concludes CBOW and Skip-gram
First, define the size of window, if the window is 2, that will be [t-2,t-1,t,t+1,t+2]
For Skip-gram, the t is used to predict the context, i.e., 2 backward and forward.
For CBOW, the context is used to predict the word in the middle.
In terms of the input of CBOW, that is the 4 words, calculate the average values, and pass into the function of softmax to get the result.
Skip-gram is similar, remove the operation of average, due to it is itself, no matter need the average.
In the word2vec, there are 2 optimised method, negative sampling and hierarchical softmax.
negative sampling means “ABCDE” - middle word is C, context is AB and DE. postive sample is CA, CB, CD, CE, which is the concurrence of word in sentence. However, it need go through the whole dictionary, waste too much resource. So, create the negative samples CC,CF, etc. It also only choose K sample randomly for the simplicity.
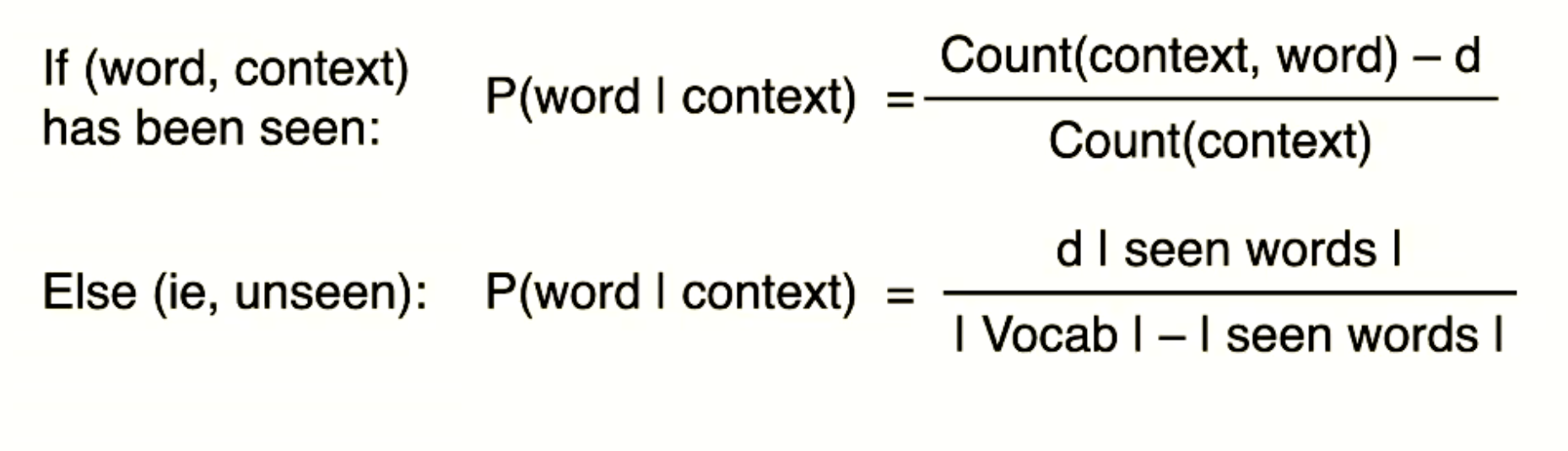
Hierarchical softmax: first create the tree with order, 霍夫曼树, the final possibility is the value times among the path that searching in the tree. binary classification for each path, get the possibility, then multiply it. It means to reduce the computational resources, comparing to the go through whole data. The operation is the similar value, not exactly accurate.
Also, there is another concept called subsampling, the possibility decided by the frequent, aiming to remove the high frequent word, like ‘the’, which no include much meaning in the word.
Comparison: CBOW train faster than Skip-gram, but Skip-gram could get better vector representation.
CBOW only predict one word, but the skip-gram predict 2K times, K means the window size. So, skip-gram will get better vector representation for low-frequent, due to its training repeat more times.